I’ve been working on a WASM interpreter from scratch. The unique feature is that it’s completely snapshotable, down to the instruction level. At any point during execution, you can call snapshot() and it will write out the entire execution state into a list of bytes, capturing everything up to that exact instruction. You can restore it later and execution picks up right where it left off.
Here’s a demo running Conway’s Game of Life. You snapshot the simulation mid-tick, fork it into a new process, and watch both diverge from the same state:
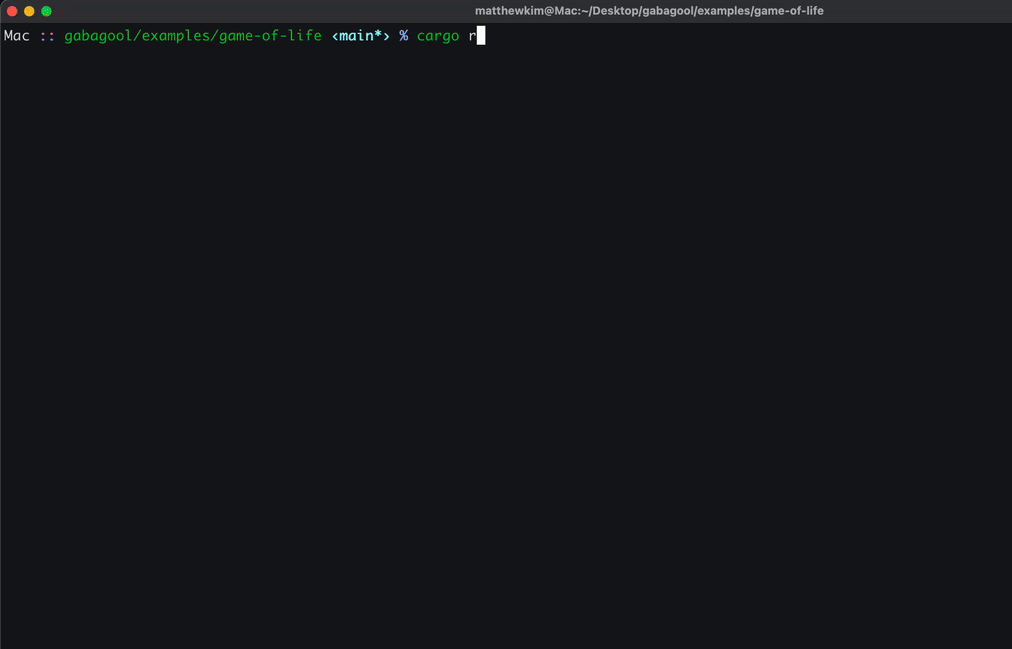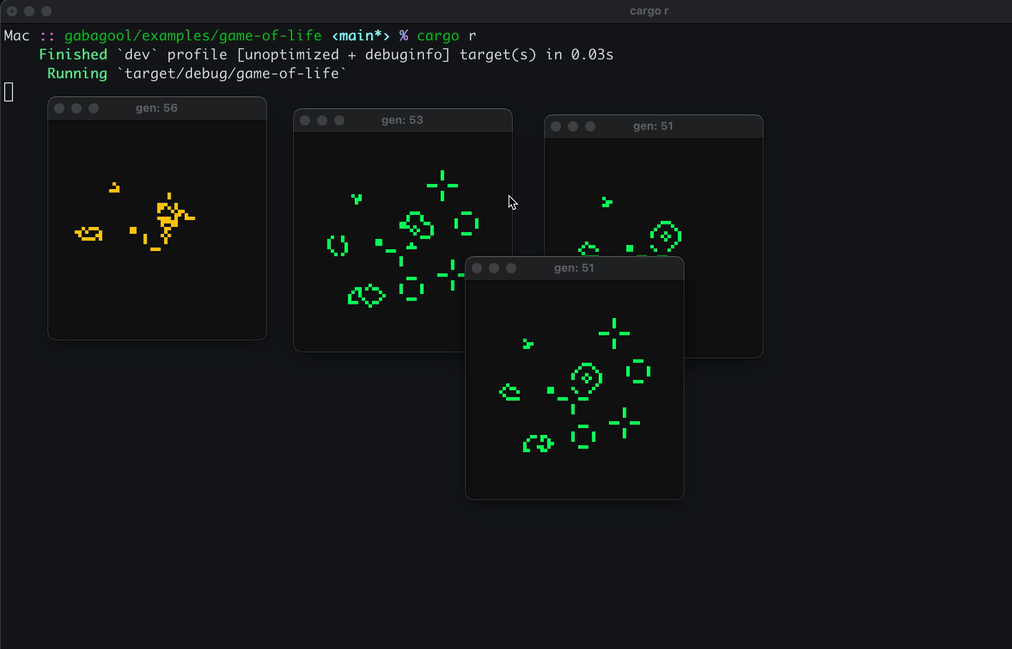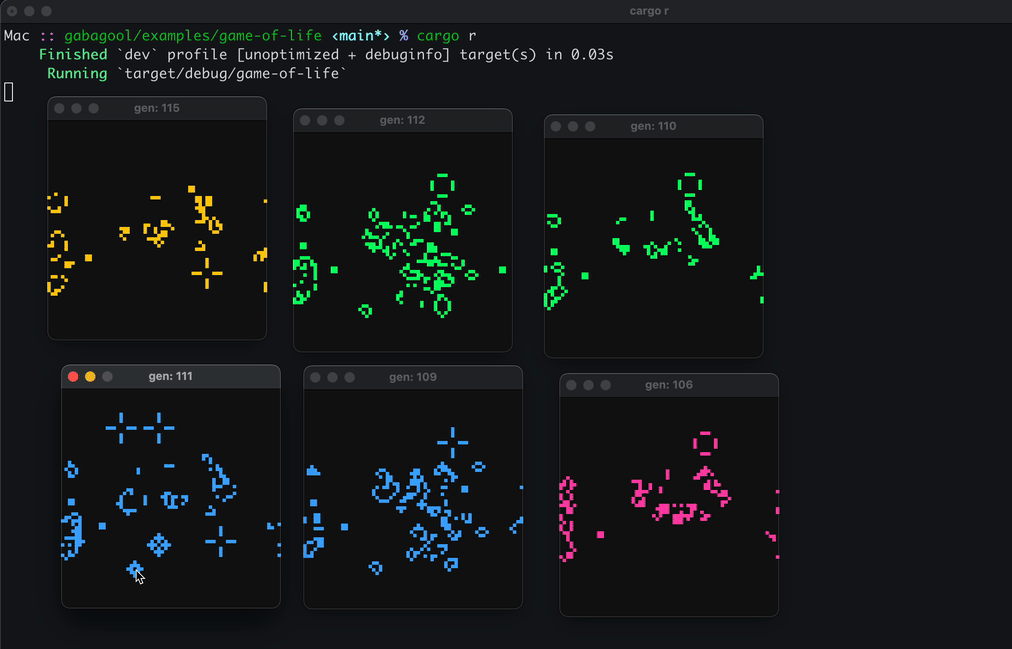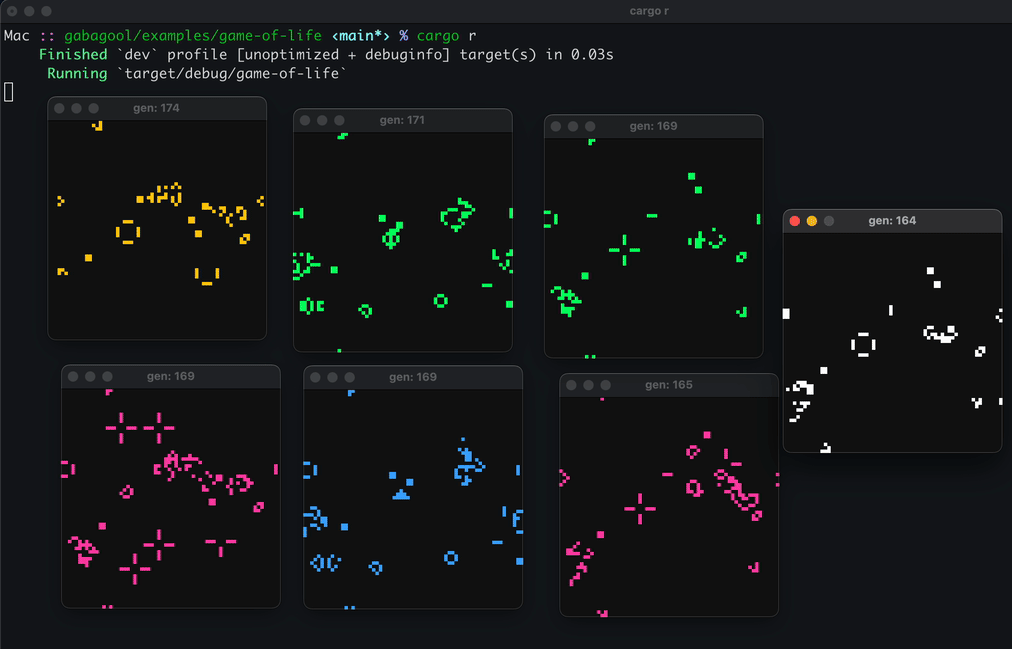
I found snapshotting an interesting feature to implement because it ties itself so well to a time travel debugger. Say you’re stepping through a program trying to track down a bug. With a normal debugger, if you step one instruction too far, you have to restart the whole session and carefully step back to where you were. A time travel debugger lets you just step backwards , or jump to any point in the program’s execution history.
, or jump to any point in the program’s execution history.
The problem space
In order to build a time travel debugger, we need a way to store history.
The most naive implementation I thought of would be to store every snapshot at every instruction. This obviously doesn’t scale well. Each snapshot from the Game of Life demo is ~1.2 MB. On a MacBook Air with 16 GB of RAM, that gives you about 13,000 snapshots before you OOM. A WASM program can burn through 13,000 instructions in milliseconds. You could only keep the $N$ most recent snapshots, but if the program hits a tight loop, all $N$ snapshots end up inside that loop and you lose all outer context.
We don’t need to store every snapshot. Given any snapshot, we can always replay forward from it and reach the same execution state. So when we want to step back to instruction 100 but our nearest snapshot is at instruction 90, we can replay forward 10 instructions to reconstruct the state.
The challenge lies in which snapshots to keep and which ones to discard. We want recent history to be dense, so stepping back 1 or 2 instructions is instant. But we also want to reach far into the past, even if the gaps are bigger there.
The nerd snipe
When I shared my project on lobste.rs, I was linked an amazing blog post. The author David Barbour introduces a data structure called an exponential decay buffer. The idea is simple: keep lots of recent snapshots and gradually fewer as you go further back. Barbour proceeds to drop some #knowledge about how you can hold deep history in very little space, at the cost of losing intermediate detail the further back you go.
about how you can hold deep history in very little space, at the cost of losing intermediate detail the further back you go.
The density of snapshots halves at a fixed interval called the half life. This turns out to be incredibly space efficient, because each half life worth of storage doubles your reach. If you can hold 1,000 snapshots with a half life of 50, you don’t just cover the last 1,000 instructions. You cover $2^{1000/50} = 2^{20} \approx$ one million instructions. Store 2,000 snapshots and you get $2^{40}$, roughly a trillion instructions.
Play with the sliders below to see how the number of snapshots and half life affect your reach:
In practice, we pick a buffer size and half life up front. Every instruction, we push a new snapshot. Once the buffer is full, each new snapshot means evicting an old one.
You could deterministically evict snapshots like evicting the $N$th oldest snapshot, but you’ll run into a problem that Barbour describes as temporal aliasing. If eviction is deterministic, it can synchronize with periodic behavior in the program. If you’re stuck in a tight loop, you’d evict snapshots at the same phase of the loop every time, creating blind spots in your history. By making eviction probabilistic, we break any synchronization. Older snapshots are still far more likely to be evicted, but which specific one gets dropped varies each time.
Barbour explains that the half life, eviction strategy, and buffer size are all tunable per application. He also concludes the blog post by dropping an implementation of the exponential buffer in Haskell.
The implementation
For the remainder of this blog post, I’ll be specific to my time travel debugger and walk through my implementation of an exponential buffer.
Our eviction strategy uses geometric sampling. When the buffer is full, we pick which snapshot to evict by sampling:
$$i = \left\lfloor \frac{\log(U)}{\log\left(1 - \frac{\ln 2}{h}\right)} \right\rfloor$$
where $U \sim \text{Uniform}(0, 1)$ and $h$ is the half life. Lower indices (older entries) are exponentially more likely to be evicted than higher indices (recent entries). The half life parameter $h$ controls the curve: an entry at index $i$ is twice as likely to be evicted as one $h$ indices closer to the newest.
The visualization below shows the eviction probability for each slot in a buffer of 100. Drag the slider to change the half life and watch how the distribution shifts. Slots on the left are older and get evicted more often (higher bar height). Slots on the right are newer and almost never touched.
For the debugger, I set the half life to 50 and buffer capacity to 1,000 snapshots. That’s $2^{1000/50} = 2^{20} \approx 1{,}048{,}576$ instructions of reachable history. And the eviction curve is steep. Old snapshots get aggressively culled while recent history stays almost untouched:
Here’s the core of the implementation. Each snapshot is stored alongside its instruction count. Since the instruction count only ever increases, the buffer is always sorted for free. That means jumping to any point in history is a binary search: find the nearest snapshot before the target instruction, then replay forward from there. For randomness, I use a simple xorshift PRNG to avoid pulling in a dependency for something this small.
type Snapshot = Vec<u8>;
struct ExponentialDecayBuffer {
// stores a list of tuples of (instruction_count, snapshot data)
buf: Vec<(u64, Snapshot)>,
capacity: usize,
half_life: f32,
rng: u64
}
impl ExponentialDecayBuffer {
pub fn new(capacity: usize) -> Self {
Self {
buf: Vec::with_capacity(capacity),
capacity,
half_life: 50.0,
// the seed
rng: 0xABBA_ABBA,
}
}
pub fn find_nearest_before(&self, instruction_count: u64) -> Option<&Snapshot> {
match self.buf.binary_search_by_key(&instruction_count, |(t, _)| *t) {
Ok(i) => Some(&self.buf[i]),
Err(0) => None,
Err(i) => Some(&self.buf[i - 1]),
}
}
pub fn push(&mut self, instruction_count: u64, snapshot: Snapshot) {
let entry = (instruction_count, snapshot);
if self.buf.len() < self.capacity {
self.buf.push(entry);
return;
}
let i = self.sample_geometric_index();
let i = i.clamp(0, self.buf.len() - 2);
self.buf.remove(i + 1);
self.buf.push(entry);
}
fn sample_geometric_index(&mut self) -> usize {
let u = self.generate_random_f32();
let i = u.log(1.0 - 2_f32.ln() / self.half_life);
i.floor() as usize
}
fn generate_random_f32(&mut self) -> f32 {
self.rng ^= self.rng << 13;
self.rng ^= self.rng >> 7;
self.rng ^= self.rng << 17;
(self.rng >> 40) as f32 / (0xFF_FFFF as f32)
}
}
What’s nice about the buffer is that it’s a clean abstraction. The debugger doesn’t have to think about what to keep or what to throw away. It just calls push with a snapshot, and the buffer handles eviction internally. When the debugger needs to step backward, it calls find_nearest_before and gets the best available snapshot. All the tricky stuff, the geometric sampling, the probabilistic eviction, the half life tuning, is hidden behind two methods.
Wiring it into the debugger is pretty simple. Every $N$ instructions, we snapshot and push it into the buffer. Stepping forward just runs an instruction. Stepping backward finds the nearest earlier snapshot, restores it, and replays forward to where we want to be. If you’re curious, here’s the actual debugger and the decay buffer used in my project. But the following is a simplified version that gets the message across:
struct Interpreter;
impl Interpreter {
fn is_completed(&self) -> bool { todo!() }
fn run_one_instruction(&mut self) { todo!() }
fn replay_forward(&mut self, n: u64) { todo!() }
fn snapshot(&self) -> Vec<u8> { todo!() }
fn restore(&mut self, snapshot: &[u8]) { todo!() }
}
enum StepResult {
Stepped,
ReachedStart,
Completed,
}
struct Debugger {
interpreter: Interpreter,
buffer: ExponentialDecayBuffer,
instruction_count: u64,
}
impl Debugger {
pub fn new(interpreter: Interpreter, mut buffer: ExponentialDecayBuffer) -> Self {
// snapshot at instruction 0 so step_back always has a base to replay from
let snapshot = interpreter.snapshot();
buffer.push(0, snapshot);
Self {
interpreter,
buffer,
instruction_count: 0,
}
}
pub fn step_forward(&mut self) -> StepResult {
if self.interpreter.is_completed() {
return StepResult::Completed;
}
self.interpreter.run_one_instruction();
self.instruction_count += 1;
// periodically snapshot
if self.instruction_count.is_multiple_of(1_000) {
let snapshot = self.interpreter.snapshot();
self.buffer.push(self.instruction_count, snapshot);
}
StepResult::Stepped
}
pub fn step_back(&mut self) -> StepResult {
if self.instruction_count == 0 {
return StepResult::ReachedStart;
}
let target = self.instruction_count - 1;
// find the latest snapshot before our target
let (snapshot_ic, snapshot) = self
.buffer
.find_nearest_before(target)
.expect("we snapshot at instruction 0");
// restore that snapshot, then replay forward to the target
self.interpreter.restore(snapshot);
self.interpreter.replay_forward(target - snapshot_ic);
self.instruction_count = target;
StepResult::Stepped
}
}